
NHN 데이터인프라랩 권동훈
Impala는 HDFS에 저장돼 있는 데이터를 SQL을 이용해 실시간으로 분석할 수 있는 시스템입니다. MapReduce 프레임워크를 이용하지 않고 분산 질의 엔진을 이용해 분석하기 때문에 빠른 결과를 제공할 수 있습니다. 아직 베타 버전이고 구현되지 않은 중요한 기능들이 있지만 많은 주목을 받고 있는 시스템입니다.
이 글에서는 Impala의 구조와 기능을 알아보고 간략한 성능 테스트를 통해 실시간 대용량 처리에서 Impala가 보여주는 성능을 확인해 보겠습니다.
Hadoop에서 실시간으로 결과 분석을
2006년 등장한 Hadoop으로 인해 대용량 데이터 분석 작업은 더 이상 소수의 몇몇 회사나 단체만이 할 수 있는 것이 아니게 되었다. Hadoop은 오픈소스여서 대용량 데이터 분석이 필요한 많은 곳에서 낮은 비용으로 쉽게 Hadoop을 사용할 수 있기 때문이다. 대용량 데이터 분석 작업이 보편적인 기술이 된 것이다.
Hadoop의 핵심은 HDFS(Hadoop Distributed File System)와 MapReduce 프레임워크다. 분산 파일 시스템 형태로 용량을 확장할 수 있는 파일 시스템인 HDFS에 데이터를 저장하고, 이렇게 저장된 데이터를 바탕으로 MapReduce 연산을 실행해 원하는 데이터를 얻어낼 수 있다.
그러나 앉으면 눕고 싶은 것이 사람의 욕심인 만큼, Hadoop 사용자 그룹은 Hadoop의 기능/성능 제약을 극복하고 Hadoop을 더 발전시키려 했다. 불만은 MapReduce 프레임워크를 사용하는 것에 좀 더 집중되었다. MapReduce 프레임워크의 대표적인 단점은 두 가지다.
- 사용하기에 불편한 점이 많다.
- 처리가 느리다.
MapReduce 프레임워크의 사용 편의성을 높이기 위해 2008년에 Pig나 Hive같은 플랫폼이 등장했다. Pig와 Hive 모두 Hadoop의 서브 프로젝트다(Hadoop은 여러 플랫폼의 생태계이기도 하다. Hadoop을 기반으로 하는 여러 제품들이 제작되고 있다). Pig와 Hive 모두 하이레벨 언어 형태라는 점에서는 같지만, Pig는 절차적인 형태임에 비해 Hive는 SQL과 유사한 선언적인 언어 형태다. Pig와 Hive의 등장으로 Hadoop 사용자들은 더 편하게 대용량 데이터 분석 작업을 수행할 수 있게 되었다.
하지만 Hive나 Pig는 데이터 조회 인터페이스에 관한 기술이라 대용량 데이터 분석 작업의 속도를 높이지는 않는다. Hive나 Pig 모두 내부적으로는 MapReduce 프레임워크를 사용한다.
그래서 등장한 것이 칼럼 기반 NoSQL인 HBase다. 키-값(Key-Value) 데이터에 대한 빠른 입출력이 가능한 HBase는 Hadoop기반의 시스템에서 실시간으로 데이터 처리가 가능한 환경을 비로소 제공했다.
Hadoop 에코 시스템(eco-System)의 이러한 발전은 Google의 영향을 많이 받았다. HDFS 자체도 Google에서 발표한 GFS(Google File System) 논문을 바탕으로 구현된 것이고, HBase 또한 Google의 BigTable 논문을 바탕으로 제작될 수 있었다. 이러한 영향 관계는 <표 1>에서 볼 수 있다.
이 글에서 소개하는 Cloudera(http://www.cloudera.com)의 Impala 또한 Google의 영향을 받았다. 2010년에 Google에서 소개한 Dremel 논문을 바탕으로 제작된 것이다. Impala는 Apache 라이선스를 가진 오픈소스며, HDFS에서 동작하는 ‘즉각적인 실시간 SQL 질의 시스템(interactive/real-time SQL queries system)’이다.
SQL은 많은 개발자들에게 친숙하다는 것뿐만 아니라, 데이터 조작과 조회를 간결하게 표현할 수 있다는 장점이 있다. Impala는 SQL을 지원하면서 실시간 대용량 데이터의 실시간 처리 기능을 제공하기 때문에, BI(Business Intelligence) 시스템으로 활용될 수 있는 잠재력을 가지고 있다. 이런 이유로 몇몇 BI 업체(vendor)들은 이미 Impala를 이용한 BI 시스템 개발을 시작했다고 한다. SQL을 이용해 실시간 분석 결과를 얻을 수 있다는 것은 빅데이터의 전망을 더욱 밝게 하는 것이고, Hadoop의 적용 외연을 넓히는 것이라 할 수 있겠다.
표 1 Google Gives Us A Map(출처: Strata + Hadoop World 2012 Keynote: Beyond Batch – Doug Cutting)
|
Google Publication |
Hadoop |
특성 |
|
GFS & MapReduce(2004) |
HDFS & MapReduce(2006) |
|
|
Sawzall(2005) |
Pig & Hive(2008) |
|
|
BigTable(2006) |
HBase(2008) |
|
|
Dremel(2010) |
Impala(2012) |
|
|
Spanner(2012) |
???? |
|
Cloudera Impala
Impala를 제작한 Cloudera는 Dremel의 논문 “Interactive Analysis of Web-Scale Datasets“을 읽고 나니 Apache와 Hadoop 위에서 실시간, 애드혹(ad-hoc) 질의가 가능할 것 같다는 기술적 영감을 얻었다고 한다.
2012년 10월 Cloudera사는 Impala를 발표하면서 다음과 같이 Impala를 소개했다.
“Real-Time Queries in Apache Hadoop, For Real”
Impala는 인터페이스로 Hive-SQL을 채택했다. 앞에서 언급했듯이 Hive-SQL은 보편적으로 사용되는 질의 언어인 SQL과 문법적으로 유사하다. 그래서 사용자가 매우 친숙한 방법으로 HDFS에 저장된 데이터에 접근할 수 있다.
Hive-SQL은 Hive의 것을 사용한 것이기 때문에, 동일 데이터에 대해 동일한 방법으로 접근할 수 있다(단, Impala는 모든 Hive-SQL을 지원하는 것은 아니다. Impala에서 사용하는 Hive-SQL을 Hive에서도 이용할 수 있다라고 이해하는 것이 좋다).
Impala와 Hive의 차이는 실시간성 여부다. Hive는 데이터 접근을 위해 MapReduce 프레임워크를 이용하는 반면에, Impala는 응답 시간을 최소한으로 줄이기 위해 고유의 분산 질의 엔진을 사용한다. 이 분산 질의 엔진은 클러스터 내 모든 데이터 노드에 설치되도록 했다.
그래서 Impala와 Hive는 동일 데이터에 대한 응답 시간에 있어서 확연한 성능 차이를 보이고 있다. Cloudera는 Impala의 성능이 좋은 이유로 다음 세 가지를 언급한다.
- Impala는 Hive보다 CPU 부하를 줄였고, 줄인 만큼 I/O 대역폭을 이용할 수 있다. 그래서 순수 I/O bound 질의의 경우 Impala는 Hive보다 3~4배 좋은 성능 결과를 보여준다.
- 질의가 복잡해지면 Hive는 여러 단계의 MapReduce 작업 또는, Reduce-side 조인(JOIN) 작업이 필요하다. 이처럼 MapReduce 프레임워크로 처리하기에 비효율적인 질의(적어도 하나 이상의 JOIN 연산이 들어간 질의)의 경우 Impala가 7~45배 정도 더 좋은 성능을 보인다.
- 분석할 데이터블록이 파일 캐시되어 있는 상태라면 매우 빠른 성능을 보여주고, 이 경우 Hive보다 20~90배 빠른 성능을 보여준다.
Real-time in Data Analytics
Impala 소개에는 실시간(real-time)이란 용어가 매우 강조되어 있다.
그럼 과연 “어느 정도의 시간을 실시간이라 말하는 것일까?”라는 의문을 누구나 한 번쯤 해 볼 만하다. 이 궁금증에 Doug Cutting(Hadoop을 만든 사람)과 Cloudera의 수석 아키텍트는 무엇을 실시간이라고 할 수 있는지 각각 다음과 같이 의견을 밝힌바 있다.
“끝날 때까지 앉아서 기다릴 수 있다면 실시간이다. 결과를 얻을 때까지 커피를 마시러 가거나, 밤새도록 가동을 시켜 놓아야 한다면 그것은 실시간이 아니다.
(It’s when you sit and wait for it to finish, as opposed to going for a cup of coffee or even letting it run overnight. That’s real time)”
“데이터 분석에서 실시간이란 ‘기다림 없음’을 추구하는 것을 말한다.
(real-time’ in data analytics is better framed as ‘waiting less.)”
실시간 판단에 대한 기준을 수치적으로 명확하게 정하는 것은 어렵겠지만, 모니터를 바라보면서 결과가 나오는 것을 기다릴 수 있다면 실시간이라 부를 만하다라고 생각할 수 있겠다.
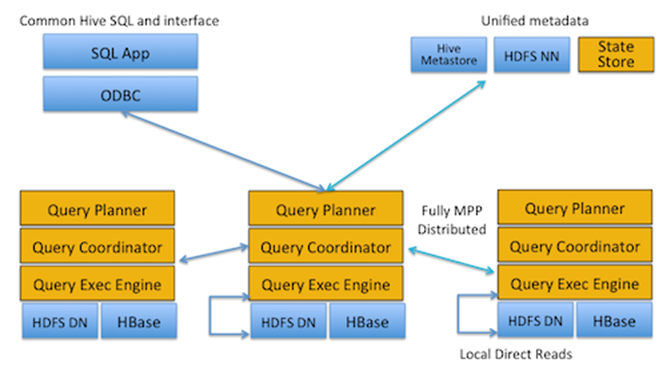
Impala 아키텍처
Impala는 크게 impalad와 impala state store라는 프로세스로 구성돼 있다.
impalad는 분산 질의 엔진 역할을 담당하는 프로세스로, Hadoop 클러스터 내 데이터노드 위에서 질의에 대한 plan 설계와 질의 처리 작업을 한다. 그리고 impala state store 프로세스는 각 데이터노드에서 수행되는 impalad에 대한 메타데이터를 유지하는 역할을 담당한다. impalad 프로세스가 클러스터 내에 추가 또는 제거될 때, impala state store 프로세스를 통해 메타데이터가 업데이트된다.
그림 1 Impala high-level architectural view(원본 출처: http://blog.cloudera.com/blog/2012/10/cloudera-impala-real-time-queries-in-apache-hadoop-for-real/)
Data locality tracking and Direct reads
Impala는 기존 Hadoop의 전통적인 분석 프레임워크인 MapReduce 프레임워크대신 impalad 프로세스가 클러스터 내 모든 데이터노드 위에서 질의를 처리하도록 했다. 이와 같은 구성에서 Impala가 얻으려는 이점 중 하나가 바로 data locality와 direct read다. 즉 자신이 속한 데이터노드에 존재하는 데이터 블록만을 처리 대상으로, 그리고 해당 데이터는 로컬 디렉터리에서 직접 읽겠다는 것이다. 이를 통해 네트워크 부하를 최소화했다. 또한 파일 캐시의 효과를 누릴 수 있는 기회가 주어지기도 한다.
Scale Out
Hadoop 클러스터와 같이 수평적 확장이 가능하다. 일반적으로 클러스터가 수평 확장을 하면 Impala도 같이 확장되면 된다. 즉 데이터노드가 추가될 때 impalad 프로세스를 해당 서버에서 실행하기만 하면 자연스럽게 확장된다(impala state store을 통해 impalad 추가에 따른 메타정보가 업데이트될 것이다). 이는 MPP(Massively Parallel Processing) 기반의 데이터베이스와 매우 유사한 모습이다.
Failover
Impala는 Hive와 HBase에 저장되어 있는 데이터를 분석한다. 그리고 Hive와 HBase가 사용하는 HDFS는 Replication을 통해 어느 정도의 failover를 제공한다. 그래서 Impala는 데이터 블록의 replica가 존재하고, 최소 한 개 이상의 impalad 프로세스가 존재한다면 질의 수행이 가능하다.
SPOF(Single Point of Failure)
HDFS를 저장매체로 이용하는 시스템의 가장 큰 고민 중 하나가 바로 네임노드가 SPOF란 점이다. 이를 방지하기 위한 솔루션이 나오고 있지만 근본적으로 해결하기는 어렵다. Impala에서도 역시 네임노드가 SPOF이다. 데이터블록의 위치를 알 수 없으면 질의 수행도 불가능해지기 때문이다.
질의 수행 절차
Impala에서 질의가 수행되는 절차를 간단하게 정리하면 다음과 같다.
- 사용자는 클러스터 내 특정 impalad를 선택해 impala shell, ODBC 등을 이용해 질의를 등록한다.
-
사용자로부터 질의를 받은 impalad는 다음과 같은 선행 작업을 수행한다.
- Hive metastore에서 테이블 스키마를 가져와 질의문의 적합성을 판단한다.
- HDFS 네임노드에서 질의 수행에 필요한 데이터 블록과 각각의 위치 정보를 수집한다.
- 최근에 업데이트된 Impala 메타데이터를 기반으로 클러스터 내 모든 impalad에게 질의 수행에 필요한 정보들을 전파한다.
- 질의와 메타데이터를 전달받은 모든 impalad는 각자 처리할 데이터 블록을 로컬 디렉터리에서 읽어와 질의 처리를 수행한다.
- 모든 impalad에서 작업이 완료되면 사용자로부터 질의를 받았던 impalad는 결과를 취합해 사용자에게 전달한다.
Impala가 지원하는 Hive-SQL
Impala는 모든 Hive-SQL을 지원하는 것은 아니다. 일부 Hive-SQL만 지원하기 때문에 어떤 구문이 지원되는지 확인해 볼 필요가 있다.
- SELECT QUERY: Impala에서는 Hive-SQL의 SELECT 관련 구문 대부분을 지원하고 있다.
-
Data Definition Language: Impala에서는 테이블을 생성하거나 변경하지 못하고 아래와 같이 데이터베이스, 테이블 스키마 조회만 가능하다. 테이블 생성 및 변경은 Hive를 통해서만 가능하다.
- SHOW TABLES
- SHOW DATABASES
- SHOW SCHEMAS
- DESCRIBE TABLE
- USE DATABASE
-
Data Manipulation: Impala는 생성되어 있는 테이블과 파티션에 데이터 추가 기능만을 제공한다.
- INSERT INTO
- INSERT OVERWRITE
-
Unsupported Language Elements: Impala에서는 다음과 같이 아직 지원하지 않는 Hive-SQL이 많이 있다. 사용하기 전에 레퍼런스()를 통해 확인해야 한다.
- Data Definition Language (DDL) such as CREATE, ALTER, DROP
- Non-scalar data types: maps, arrays, structs
- LOAD DATA to load raw files
- Extensibility mechanisms such as TRANSFORM, custom User Defined Functions (UDFs), custom file formats, custom SerDes
- XML and JSON functions
- User Defined Aggregate Functions (UDAFs)
- User Defined Table Generating Functions (UDTFs)
- Lateral Views
Data Model
현재 베타 버전인 Impala에서는 텍스트 파일과 Hadoop sequence file만을 입력 포맷으로 지원하고 있다. 추후 Snappy, Gzip, Bzip과 같은 압축 파일 포맷도 지원한다고 한다.
그러나 최대 관심사는 바로 column file format인 Trevni의 지원이다. Impala에서 Trevni 지원이 중요한 관심사인 이유는 Trevni 지원으로 지금보다 더 나은 성능을 제공해 줄 수 있기 때문이다. 아직 Trevni는 개발 진행 중이기 때문에, Dremel 논문에서 언급된 column file format 내용을 잠시 소개하겠다.
Trevni
Trevni는 Doug Cutting이 현재 진행 중인 프로젝트로, rows와 columns로 이뤄진 테이블 레코드를 기존의 row-major format이 아닌 column-major format으로 저장하는 파일 포맷이다. Trevni에 관한 자세한 내용은 http://avro.apache.org/docs/current/trevni/spec.html를 참조한다.
Dremel 논문에서는 성능에 영향을 주는 요소 중 하나로 칼럼 파일 포맷(Column File Format)을 말하고 있다. 칼럼 파일 포맷으로 가장 크게 이득을 보는 부분이 바로 디스크 I/O다. 칼럼 파일 포맷은 하나의 레코드를 각각의 칼럼으로 분할해 쓰기 때문에, 레코드에서 일부 칼럼만을 조회할 때 더 큰 효과를 본다. 기존 로우 단위 저장 방식으로는 하나의 칼럼을 보거나 전체 칼럼을 보나 동일한 디스크 I/O가 발생할 수 있지만, 칼럼 파일 포맷에서는 필요한 칼럼 접근 시에만 디스크 I/O가 일어나기에 더 효율적으로 디스크 I/O를 사용할 수 있다는 장점이 있다.
그림 2 로우 단위 저장과 칼럼 단위 기반의 비교 (출처: Dremel: Interactive Analysis of Web-Scale Datasets)
Dremel에서 칼럼 파일 포맷에 관련해 수행한 두 가지 테스트 결과를 보면 칼럼 파일 포맷이 성능에 기여하는 정도를 가늠해 볼 수 있다.
그림 3 칼럼 단위 저장과 로우 단위 저장의 성능 비교 (출처: Dremel: Interactive Analysis of Web-Scale Datasets)
<그림 3>에서 (a), (b), (c)는 칼럼 파일 포맷에서 랜덤하게 선택된 칼럼의 개수에 따른 수행 시간을 보여주고 있고, (d), (e)는 기존 레코드(record)를 읽는 수행 시간을 보여주고 있다. 테스트 결과를 보면 칼럼 파일 포맷의 수행 시간이 빠르다. 특히 적은 수의 칼럼을 접근할 때 수행 시간의 차이는 더 벌어진다. 기존 방법으로 레코드를 읽을 때는 하나의 칼럼에 접근해도 항상 전체를 읽는 것과 같은 최악의 수행 시간을 보여주지만, 칼럼 파일 포맷(a, b, c)은 선택된 칼럼 개수가 적을수록 더 좋은 성능을 보여준다.
그림 4 칼럼 단위 저장과 로우 단위 저장에서 MapReduce를수행 했을 때와 Dremel에 대한 성능 비교 (300nodes, 85 billion records) (출처: Dremel: Interactive Analysis of Web-Scale Datasets)
<그림 4>는 MapReduce 작업을 칼럼 파일 포맷 데이터로 처리하는 경우와 그렇지 않은 경우에 따른 수행 시간을 보여준다(MapReduce와 Dremel과의 비교 테스트지만 그 이전에 칼럼 파일 포맷을 MapReduce에 적용/미적용한 결과만을 보도록 하자). 이처럼 칼럼 파일 포맷은 디스크 I/O를 줄이는 방법으로 상당한 성능 향상을 보여주고 있다.
물론 위의 내용과 실험 결과는 Dremel에서 구현된 칼럼 파일 포맷에 대한 것이기에 Impala에 적용될 Trevni의 결과는 이와 다를 수 있다. 그렇지만, Trevni도 Dremel에서 보여준 칼럼 파일 포맷과 같은 목표로 개발되고 있기에 위 테스트와 비슷한 결과를 보여줄 것으로 기대할 수 있다.
Impala 설치, 설정, 가동
설치
Impala을 설치하려면 기본적으로 아래와 같은 소프트웨어가 필수적으로 설치돼 있어야 한다. Impala 설치 방법에 관한 자세한 정보는 “Installing and Using Cloudera Impala” 문서에서 얻을 수 있다.
- Red Hat Enterprise Linux(RHEL)/CentOS 6.2(64bit) 이상
- Hadoop 2.0
- Hive
- MySQL
MySQL은 Hive metastore로 사용하기 위해서 필수적이다. Hive에서는 metastore으로 사용할 수 있는 다양한 데이터베이스를 지원하고 있다. 하지만 Impala와 Hive가 연동되기 위해서는 현재는 MySQL로 연동되어야 한다. Hive metastore에 설치에 관한 자세한 내용은 “Configuring Impala for Performance” 문서를 참조한다.
만약 HBase와의 연동이 필요하다면 HBase설치도 필요하다. 여기서는 각 소프트웨어의 자세한 설치 방법은 생략하겠다.
필요한 소프트웨어가 모두 설치됐다면 Impala 패키지를 클러스터 내 모든 데이터노드에 설치한다. 그리고 클라이언트 호스트에는 impala shell을 설치한다.
설정
impalad가 로컬 디렉터리에서 HDFS의 파일 블록(file block)에 직접 접근하기 위해서, 그리고 locality tracking을 위해 Hadoop의 core-site.xml 파일과 hdfs-site.xml 파일에 몇 가지를 설정해야 한다. 이 부분은 Impala의 성능에 매우 중요한 설정이니 잊지 않고 추가해야 한다. 변경 후에는 HDFS를 재부팅해야 한다. 더 자세한 내용은 “Configuring Impala for Performance” 문서를 참조한다.
가동
현재 Impala에서는 테이블 생성 및 데이터 로딩이 지원되지 않기 때문에 Impala를 실행하기 전에 Hive Client를 통한 테이블 생성 및 데이터 로딩이 선행 작업으로 이뤄져야 한다. 만약 HBase에 존재하거나 새롭게 생성될 테이블 분석이 필요하다면 Hive를 통해 extern table로 재정의해 사용한다. 더 자세한 내용은 “Hive HBase Integration” 문서를 참조한다.
Impala에 질의를 입력하는 방법에는 impala shell이나 Cloudera Beeswaw, ODBC를 통하는 방법이 있다. Beeswax는 사용자가 쉽게 Hive를 이용하도록 도와주는 애플리케이션이다. 여기서는 impala shell을 이용한 질의 방법을 예로 들어보겠다.
$sudo –u impala impala-shell Welcome to the Impala shell. Press TAB twice to see a list of available commands. Copyright (c) 2012 Cloudera, Inc. All rights reserved. (Build version: Impala v0.1 (1fafe67) built on Mon Oct 22 13:06:45 PDT 2012) [Not connected] > connect impalad-host:21000 [impalad-host:21000] > show tables custom_url [impalad-host:21000] > select sum(pv) from custom_url group by url limit 50 20390 34001 3049203 [impalad-host:21000] >
질의 입력에 앞서 클러스터 내 impalad 중에서 메인 서버가 될 impalad를 하나 선택해 접속한다. 접속이 완료되면 원하는 질의를 입력해 결과를 확인해 보자.
Impala 기능/성능 테스트
아직 Impala가 베타 버전이고 해결되지 않은 문제들이 있지만, 사용 가능한 범위 내에서 어느 정도의 성능을 보여주는지 간단하게 테스트해 보았다.
사용한 장비와 설치된 소프트웨어 버전은 <표 2>와 같고 Hadoop 클러스터는 Namenode/JobTracker 1대, Data/Task node는 3~5대, 그리고 commander 1대로 구성했다. 그리고 HDFS replication은 “2”로 설정했다. 노드의 Map/Reduce capacity는 각각 “2”다.
테스트를 위한 데이터는 14개의 칼럼 데이터를 가진 약 13억 개의 레코드며, 크기가 약 65GB 정도다.
표 2 하드웨어 및 소프트웨어 버전
|
구분 |
정보 |
|
|
장비 |
CPU |
Intel Xeon 2.00GHz |
|
Memory |
16GB |
|
|
소프트웨어 |
OS |
CentOS release 6.3(Final) |
|
Hadoop |
2.0.0-cdh4.1.2 |
|
|
HBase |
0.92.1-cdh4.1.2 |
|
|
Hive |
0.9.0-cdh4.1.2 |
|
|
Impala |
0.1.0-beta |
테스트에 사용한 테이블은 15개의 칼럼으로 이뤄진 단순한 형태며, 질의는 SQL에서 많이 사용하는 SELECT, FROM,. GROUPBY, ORDERBY, LIMIT로 구성했다.
예제 2 테스트 질의
select …. from xxx WHERE …. group by sr, url order by sumvalue desc limit 50
테스트 수행 결과
테스트는 3대와 5대의 클러스터의 규모에서 동일한 테이블에 동일한 질의를 Impala와 Hive를 통해서 수행했고, 각각의 평균 응답시간을 측정했다.
표 3 클러스터 규모 별 Impala, Hive에서 동일 질의에 대한 수행 시간 비교
|
Impala |
Hive |
Hive/Impala |
|
|
3 노드 |
265s |
3,688s |
13.96 |
|
5 노드 |
187s |
2,377s |
13.71 |
앞에서 소개했듯이 Impala는 MapReduce를 이용한 분석 작업보다 월등하게 뛰어난 성능을 보여준다. 그리고 클러스터 규모가 커짐에 따라 선형적으로 더 나은 응답 시간을 보여주고 있다(클러스터 확장 후 rebalance를 통해 데이터 블록을 균등하게 분산 배치 후 테스트했다).
그림 5 클러스터 규모에 따른 Impala 응답 속도
추가로 현재 많이 이용하고 있는 상용 데이터베이스를 대상으로도 테스트해 봤다. Impala와 MPP란 공통분모를 가지고 있는 칼럼 기반의 상용 데이터베이스인 Infobright, infiniDB, 그리고 Vertica에서 동일한 데이터와 질의로 테스트했다. Infobright, infiniDB는 오픈소스, Vertica는 커뮤니티 에디션 버전을 이용했다. 이 3개의 데이터베이스에 대한 테스트는 1개의 서버에서 수행했다.
표 4 칼럼 기반의 상용 데이터베이스 수행 속도
|
데이터베이스 |
수행 시간 |
|
Infobright |
200s |
|
infiniDB |
32s |
|
Vertica |
15s |
<표 4>의 테스트 결과에서 알 수 있듯이, 상용 엔터프라이즈 제품인 Infobright, infiniDB, Vertica가 Impala보다는 훨씬 더 좋은 수행 결과를 내고 있다. Impala는 아직 개발 초기 단계여서 구조적, 기술적으로 미흡한 면이 있을 수 있기 때문이다.
가장 성능이 좋은 Vertica의 경우 3대 서버로 확장했을 때 <표 4>의 자료보다 30% 정도 더 나은 성능을 보였다. 하지만 상용 제품인 만큼 2대 이상의 클러스터로 구성하려면 높은 비용을 지불해야 한다는 것이 단점이라 할 수 있다.
마치며
Impala가 세상에 소개된 지 한 달 정도 밖에 되지 않았다. 아직 베타 버전이라 많은 자료나 데이터가 없는 상황이며 지원하는 파일 포맷도 한정적이다. JOIN 연산 시 서버 메인 메모리보다 큰 데이터라 할지라도 in-memory 처리를 해 OOM(Out Of Memory) 발생과 같은 위험 요소를 가지고 있는 등 기술적 한계가 있지만, 2013년 1/4분기로 계획 된 production release에는 Trevni 지원 등 많은 부분이 개선될 것으로 보인다.
또한 이와 별개로, Cloudera와 같이 Hadoop을 이용해 사업을 하는 MapR은 본사 개발자들을 주축으로 Impala와 같이 Dremel 논문 기반의 시스템인 “Drill“을 Apache incubator에 제안했다. 말 그대로 아직 Proposal 상태이긴 하지만, MapR 개발자들이 주축으로 이뤄진 프로젝트라 시작된다면 빠르게 진행되지 않을까 기대한다.
- NHN 데이터인프라랩 권동훈
- 2008년부터 데이터인프라랩에서 대용량 데이터 저장 및 분석 시스템을 개발 및 성능향상 작업을 해왔다. 현재는 대용량 실시간 스트림 분석 분야에 관심을 가지고 있으며, 이와 관련해서 다양한 시도를 해보고 있다.