
NHN Business Platform 클라우드플랫폼개발랩 박민수
클라우드 환경에서는 간단한 사용자 조작으로 네트워크 부하를 분산하고 트래픽을 모니터링하며 서로 다른 데이터 센터나 서로 다른 지역 또는 서로 다른 국가에서 운영 중인 서버에 대해 네트워크를 관리할 수 있도록 하는 기술이 필요합니다. 이번 글에서는 클라우드 네트워크를 효율적으로 관리할 수 있는 기술 중 하나인 OpenFlow에 대해서 이야기하겠습니다.
클라우드 환경의 네트워크 관리
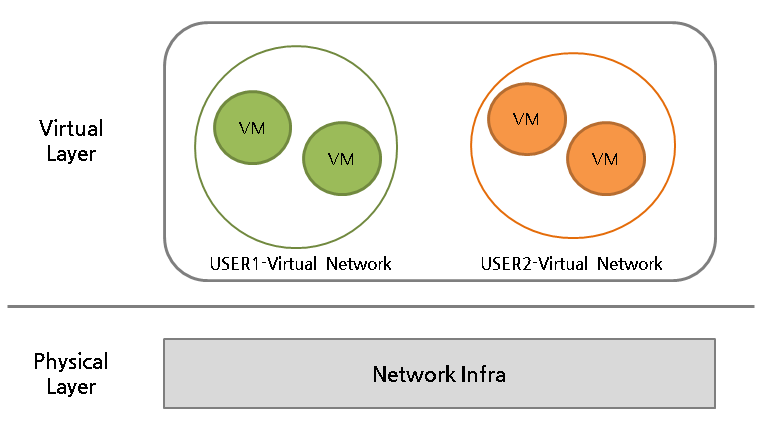
클라우드 서비스에는 다음 그림과 같이, 하나의 물리 서버에서 하나 이상의 가상 머신(virtual machine, 이하 VM)을 제공하는 서버 가상화 기술뿐만 아니라, 물리 네트워크에서 가상의 네트워크 환경을 제공하는 네트워크 가상화 기술도 적용되어 있다.
그림 1 클라우드 네트워크 구성
이와 같은 클라우드 환경에서는 몇 가지 사항이 만족돼야 한다.
첫 번째는 보안(security)이다. 공통의 물리 네트워크 인프라를 여러 명의 사용자가 공유해서 사용해야 하기 때문에, 가상 네트워크 인프라에서는 서로 다른 사용자의 VM 간에 보안이 보장되어야 한다.
두 번째는 자동화(automation)이다. 일반적인 서비스 환경에서는 네트워크 설정 정보를 추가하거나 변경하려면 네트워크 관리자에게 요청해야 하며, 완료되기까지 시간이 소요된다. 하지만 클라우드 환경에서는 사용자가 간단히 조작하여 네트워크를 설정하고 설정이 즉시 반영될 수 있어야 한다. 이를 위해서는 요청이 즉시 반영될 수 있도록 자동화해야 한다.
세 번째는 확장성(scalability)이다. 클라우드 서비스의 장점 중 하나는 필요한 VM을 빠른 시간 내에 투입할 수 있다는 것이다. 이렇게 투입된 VM의 지역이나 국가가 다르거나, 전체 VM 수가 수백 대 또는 수천 대여도 쉽게 네트워크 환경을 구축할 수 있어야 한다.
보안, 자동화, 확장성을 보장하려면 네트워크 기술이 다음의 조건을 만족해야 한다.
- 자유롭게 네트워크를 만들고 다양한 서비스를 제공할 수 있도록 유연성이 있어야 한다.
- 네트워크를 동적으로 관리할 수 있도록 기능이 모듈화되어 있어야 한다.
- 위 두 가지를 만족하기 위해서는 네트워크 요소들을 프로그래밍할 수 있어야 한다.
위 조건을 모두 만족시키는 아키텍처 중 하나로 SDN(Software Defined Network)이 있다.
SDN
학교나 연구소는 새로운 네트워크 프로토콜을 개발하고 테스트하고 싶어 한다. 그런데 테스트하기 위해 별도의 네트워크 환경을 구축하려면 비용이 많이 들고, 운영 중인 네트워크 환경에서 새로운 프로토콜을 테스트하면 장애를 유발하는 등 운영에 영향을 미칠 가능성이 있다. 이로 인해 하나의 물리 네트워크 환경에서 다수의 가상 네트워크 환경을 구축할 수 있는 방법을 연구하기 시작했고, 그 결과 SDN이라는 개념이 등장했다.
다음 그림에서 보는 것처럼, 네트워크 장비가 포함된 인프라 계층은 단순히 패킷을 전달하는 역할만 하고, SDN 제어 소프트웨어를 프로그래밍하여 패킷의 흐름을 제어하므로 하나의 네트워크 인프라에서 다양한 네트워크 환경을 구축할 수 있다. 즉, SDN에서는 패킷이 발생했을 때 네트워크 장비는 패킷을 어디로 전달할지 SDN 제어 소프트웨어에게 물어보고, 그 결과를 반영하여 패킷을 전송하는 경로와 방식을 결정한다.
그림 2 SDN 아키텍처(이미지 출처: https://www.opennetworking.org/sdn-resources/sdn-defined)
하지만 SDN은 이론적인 개념으로, 실제로 적용하려면 이를 구현할 방안이 필요했다. 이 SDN을 구현하기 위해 Stanford University에서 제안한 내용이 OpenFlow이다.
OpenFlow 소개
OpenFlow는 SDN을 구현하기 위해 처음으로 제정된 표준 인터페이스이다. 다음 그림과 같이 OpenFlow 스위치, OpenFlow 컨트롤러로 구성되며, 흐름(flow) 정보를 제어하여 패킷의 전달 경로 및 방식을 결정한다.
흐름
흐름(flow)은 “특정 시간 동안 네트워크상의 지정된 관찰 지점을 지나가는 패킷의 집합”이라고 정의된다. 간단히 이야기하면 흐름이란 패킷의 출발지와 목적지 정보 등을 가진 데이터라고 할 수 있다(“네트워크 트래픽 분석 기술, NetFlow 소개와 활용” 참조).
그림 3 OpenFlow 시스템 구성(이미지 출처:
OpenFlow 동작 방식
OpenFlow 스위치 내부에는 패킷 전달 경로와 방식에 대한 정보를 가지고 있는 FlowTable이라는 것이 존재한다. 패킷이 발생하면 제일 먼저 FlowTable이 해당 패킷에 대한 정보를 가지고 있는지 확인한다. 패킷에 대한 정보가 존재하면 그에 맞춰 패킷을 처리하고, 정보가 존재하지 않으면 해당 패킷에 대한 제어 정보를 OpenFlow 컨트롤러에 요청한다.
스위치로부터 제어 정보를 요청받은 OpenFlow 컨트롤러는 내부에 존재하는 패킷 제어 정보를 확인하고, 해당 결과를 OpenFlow 스위치에 전달한다. OpenFlow 컨트롤러 내의 패킷 제어 정보는 외부의 프로그램에서 API를 통해 입력할 수 있다.
OpenFlow 스위치는 컨트롤러로부터 전달 받은 제어 정보를 FlowTable에 저장하고, 이후 동일한 패킷이 발생하면 FlowTable에 있는 정보를 활용하여 패킷을 전달한다.
OpenFlow 패킷 제어 정보
앞에서 언급했듯이 OpenFlow에서 패킷을 제어하는 정보는 FlowTable에 저장되어 있으며, 다음 그림과 같이 Header Fields, Counters, Actions로 구성된다.
그림 4 Flow Entry 구성 요소
헤더 필드(header fields)에는 스위치 포트, 이더넷 및 프로토콜 정보, 출발지(source)/목적지(destination)의 MAC·IP·포트·우선순위가 저장된다. 헤더 필드 정보와 패킷의 정보의 일치 여부에 따라, 발생한 패킷이 FlowTable에 존재하는지 결정한다.
액션(actions)은 패킷 정보가 헤더 필드 정보와 일치할 때 어떻게 패킷을 처리할지에 대한 정보를 담고 있으며, 처리 방식은 다음 3가지가 있다.
- 스위치에 정의되어 있는 경로에 따라 패킷 전달
- 정해진 하나의 포트 또는 여러 개의 포트로 패킷 전달(전달 경로 변경)
- 패킷이 더 이상 전달되지 못하도록 차단(drop)
카운터(counters)는 FlowTable에 제어 정보가 등록된 순간부터 현재까지의 시간을 측정하는 용도로 사용된다. FlowTable에 등록된 제어 정보는 영구적으로 저장하거나 정해진 시간 동안만 유지할 수 있는데, 카운터는 후자의 경우 생명 주기(life cycle) 관리에 사용된다.
OpenFlow 적용 예
앞에서 클라우드 환경의 네트워크는 보안, 자동화, 확장성을 보장해야 한다고 했는데, OpenFlow에서 이를 어떻게 보장하는지 살펴보자.
다음과 같은 2명의 사용자가 생성한 VM 그룹이 있다고 가정해 보자.
그림 5 OpenFlow 적용 예
보안을 위해서는 각 사용자가 생성한 VM끼리만 통신할 수 있어야 하는데, OpenFlow의 FlowTable을 다음과 같이 구성하면 이를 해결할 수 있다.
표 1 FlowTable 설정 예
|
SrcIp |
DestIp |
Protocol |
SrcPort |
DestPort |
Priority |
… |
Action |
|
10.0.0.2 |
10.0.0.3 |
* |
* |
* |
0 |
* |
NORMAL |
|
10.0.0.3 |
10.0.0.2 |
* |
* |
* |
0 |
* |
NORMAL |
|
10.0.0.4 |
10.0.0.5 |
* |
* |
* |
0 |
* |
NORMAL |
|
10.0.0.5 |
10.0.0.4 |
* |
* |
* |
0 |
* |
NORMAL |
|
* |
* |
* |
* |
* |
65535 |
* |
DROP |
10.0.0.2, 10.0.0.3 간의 패킷과 10.0.0.4, 10.0.0.5 간의 패킷만 전달하고 다른 모든 패킷은 drop하도록 설정되어 있다.
네트워크 설정을 자동화하려면 VM이 생성될 때마다 자동으로 위와 같이 설정되어야 한다. 외부 프로그램에서 API로 OpenFlow 컨트롤러에 정보를 입력할 수 있으므로, 해당 VM이 생성될 때 관리 프로그램에서 API를 호출해 관련 정보를 설정하도록 하면 이 또한 쉽게 해결할 수 있다.
그리고 확장성을 보장하려면 네트워크 환경을 쉽게 구축할 수 있어야 한다. OpenFlow 스위치를 추가할 때에는 기존의 OpenFlow 컨트롤러와 연결하기만 하면 되고, OpenFlow 컨트롤러를 추가할 때에는 API로 패킷 제어 정보를 일괄 등록하고 OpenFlow 스위치와 연결하기만 하면 된다. 따라서 쉽고 빠르게 네트워크 환경을 구축할 수 있다.
마치며
OpenFlow는 그 개념이 정립되고 적용되기 시작한 지 몇 년밖에 안 된, 성숙되지는 않은 기술이다. 이 번 글을 통해 향후 시장이 성숙되면 클라우드 환경에서 꼭 필요한 기술이 될 것이라고 생각되는 OpenFlow에 대해 이해하는데 도움이 되었기를 바란다.
참고 자료
- NBP 클라우드플랫폼개발랩 박민수
- Hadoop을 이용한 분석 시스템 개발로 입문해서 지금은 클라우드 서비스를 개발하고 있다. 배워야 할게 너무 많지만 새로운 것을 알아가며 하루 하루를 즐겁게 보내려고 노력하는 개발자이다.